Python, một ngôn ngữ lập trình đa năng, ngày càng khẳng định vị thế vượt trội trong lĩnh vực thống kê, phân tích dữ liệu và khoa học dữ liệu. Nếu bạn đã có kiến thức cơ bản về thống kê, việc áp dụng chúng vào Python sẽ giúp bạn xử lý dữ liệu nhanh chóng và hiệu quả hơn rất nhiều so với phương pháp thủ công. Bài viết này sẽ hướng dẫn bạn cách bắt đầu hành trình khai phá dữ liệu với Python.
Tại Sao Python Là Lựa Chọn Hàng Đầu cho Phân Tích Dữ Liệu?
Nhiều người có thể thắc mắc tại sao lại chọn Python thay vì các công cụ bảng tính quen thuộc như Excel, LibreOffice Calc hay Google Sheets cho việc phân tích dữ liệu. Lý do chính nằm ở khả năng mở rộng và kho thư viện đồ sộ mà Python mang lại.
Ưu thế vượt trội so với bảng tính truyền thống
Các bảng tính chủ yếu được thiết kế cho các phép tính kinh doanh và tài chính cơ bản. Mặc dù bạn có thể thực hiện một số tính toán nâng cao, nhưng chúng vẫn bị giới hạn đáng kể so với những gì Python có thể làm. Python cho phép bạn tiếp cận hàng loạt thư viện chuyên dụng, mở ra cánh cửa cho các phân tích phức tạp hơn rất nhiều.
 Biểu đồ dữ liệu laptop trong phần mềm bảng tính LibreOffice Calc, minh họa hạn chế của spreadsheet khi xử lý dữ liệu lớn so với Python.
Biểu đồ dữ liệu laptop trong phần mềm bảng tính LibreOffice Calc, minh họa hạn chế của spreadsheet khi xử lý dữ liệu lớn so với Python.
Vấn đề thứ hai là khả năng mở rộng. Bảng tính hoạt động tốt với các bộ dữ liệu nhỏ, nhưng khi gặp dữ liệu lớn, việc thao tác trở nên chậm chạp và kém hiệu quả. Để thực hiện các phép tính trên nhiều hàng, bạn thường phải kéo và thả, điều này rất tốn thời gian và công sức nếu dữ liệu kéo dài qua nhiều màn hình.
Thư viện phong phú và khả năng mở rộng
Với các thư viện chuyên biệt như NumPy, pandas, Seaborn, và Pingouin, các thao tác dữ liệu trong Python trở nên hiệu quả hơn nhiều khi làm việc với khối lượng dữ liệu lớn. Bạn có thể thực hiện các phép toán phức tạp, chọn lọc dữ liệu từ nhiều cột và tính toán trên chúng chỉ trong một hoặc vài dòng lệnh.
Hiệu quả và tự động hóa với dữ liệu lớn
Điều tuyệt vời hơn nữa là khả năng viết các script để tự động hóa các thao tác này. Bạn chỉ cần nhập lệnh một lần duy nhất, sau đó có thể tái sử dụng cho các bộ dữ liệu tương tự, tiết kiệm đáng kể thời gian và công sức.
Mặc dù vậy, bảng tính vẫn có chỗ đứng riêng. Chúng rất hữu ích cho các thao tác nhanh chóng hoặc để định dạng dữ liệu trước khi nhập vào Python. Với các yêu cầu định dạng chặt chẽ như độ dài ký tự hay kiểu dữ liệu số nguyên, một hệ quản trị cơ sở dữ liệu nhỏ gọn như SQLite thậm chí còn tốt hơn.
Bài viết này tập trung vào việc sử dụng các thư viện Python cho các phép tính thống kê cơ bản và sẽ không đi sâu vào lý thuyết. Nếu bạn muốn tìm hiểu về lý thuyết thống kê, có rất nhiều tài liệu trực tuyến và ngoại tuyến miễn phí như sách giáo khoa của OpenStax hoặc các khóa học trên Khan Academy.
Thiết Lập Môi Trường Làm Việc Với Python cho Thống Kê
Để bắt đầu phân tích dữ liệu với Python, bạn cần cài đặt một số thư viện quan trọng đã được đề cập. Bài viết này giả định bạn đang sử dụng hệ thống giống Unix (Linux, macOS) hoặc Windows với Windows Subsystem for Linux (WSL) đã được cài đặt.
Cài đặt Mamba: Trình quản lý gói hiệu quả
Thứ đầu tiên bạn cần cài đặt là Mamba, một trình quản lý gói mạnh mẽ dành cho các thư viện này. Mặc dù hầu hết các hệ điều hành Linux đều có trình quản lý gói riêng, nhưng chúng chủ yếu quản lý hệ điều hành, không phải các dự án lập trình của bạn. Các nhà phát triển thường muốn phiên bản thư viện mới hơn so với các bản phân phối chính thống. Mamba cung cấp một lựa chọn thứ ba: cho phép bạn vận hành một hệ thống cơ bản ổn định trong khi vẫn cung cấp quyền truy cập vào các gói phát triển mới hơn. Bạn có thể làm theo hướng dẫn trên trang web của Mamba để cài đặt, thường chỉ cần dán một đoạn script vào terminal.
Tạo và kích hoạt môi trường thống kê
Sau khi Mamba được cài đặt, bạn cần tạo một môi trường riêng biệt để tránh xung đột giữa các gói. Chúng ta sẽ tạo một môi trường có tên “stats” và cài đặt các thư viện cần thiết vào đó.
Trước tiên, hãy tạo môi trường “stats”:
mamba create -n statsSau đó, kích hoạt môi trường này:
mamba activate stats Màn hình terminal Linux hiển thị lệnh kích hoạt môi trường Mamba và khởi động IPython, hướng dẫn thiết lập môi trường phân tích dữ liệu Python.
Màn hình terminal Linux hiển thị lệnh kích hoạt môi trường Mamba và khởi động IPython, hướng dẫn thiết lập môi trường phân tích dữ liệu Python.
Cài đặt các thư viện cần thiết: NumPy, pandas, SciPy, Seaborn, Pingouin, IPython
Với môi trường đã được kích hoạt, giờ đây chúng ta có thể cài đặt các gói. Các thư viện sẽ được sử dụng trong bài viết này bao gồm NumPy, pandas, SciPy, Seaborn và Pingouin. Chúng ta cũng sẽ cài đặt IPython, vì nó rất tiện lợi cho việc sử dụng tương tác hơn trình thông dịch Python tiêu chuẩn.
mamba install ipython numpy pandas scipy seaborn pingouinKhi môi trường đã được thiết lập, chúng ta có thể bắt đầu với các phép tính.
Bắt Đầu Với Dữ Liệu: Nhập và Tạo Dữ Liệu Trong Python
Để thực hiện các phép tính thống kê, bạn sẽ cần dữ liệu. Đó có thể là dữ liệu bạn đã có, như một bảng tính Excel, hoặc dữ liệu bạn tải xuống từ các trang như Kaggle. Seaborn và Pingouin cũng có thể truy cập các bộ dữ liệu công khai để bạn thực hành và học hỏi.
Để bắt đầu, hãy đảm bảo môi trường “stats” đang hoạt động, sau đó chạy IPython:
ipythonChúng ta sẽ bắt đầu bằng cách nhập thư viện pandas:
import pandas as pdĐọc dữ liệu từ file CSV/Excel với pandas DataFrame
Pandas có các phương thức để đọc từ các định dạng tệp dữ liệu phổ biến, bao gồm Excel (.xls) và định dạng giá trị phân tách bằng dấu phẩy (.csv), vốn rất phổ biến trong phân tích dữ liệu.
Chúng ta sẽ sử dụng phương thức read_csv của pandas để đọc một tệp. Ví dụ, với dữ liệu giá laptop:
data = pd.read_csv("data/laptop_prices.csv")Lệnh này sẽ tạo một cấu trúc dữ liệu gọi là “DataFrame,” tương tự như một bảng tính hoặc cơ sở dữ liệu quan hệ. Hãy hình dung nó như một bảng chứa dữ liệu của bạn. Bạn có thể xem vài hàng đầu tiên bằng cách gọi phương thức head() trên DataFrame:
data.head() Kết quả hiển thị các hàng đầu tiên của DataFrame trong IPython sử dụng phương thức head() của Pandas, minh họa cách xem dữ liệu sau khi nhập vào Python.
Kết quả hiển thị các hàng đầu tiên của DataFrame trong IPython sử dụng phương thức head() của Pandas, minh họa cách xem dữ liệu sau khi nhập vào Python.
Tạo dữ liệu ngẫu nhiên với NumPy cho mục đích thử nghiệm
Bạn cũng có thể tự tạo dữ liệu bằng cách tạo ngẫu nhiên. Điều này rất tốt để tạo dữ liệu thử nghiệm. Bạn có thể sử dụng bộ tạo số ngẫu nhiên của NumPy cho mục đích này.
Đầu tiên, nhập NumPy:
import numpy as npSau đó, chúng ta sẽ tạo một bộ tạo số ngẫu nhiên:
rng = np.random.default_rng()Chúng ta có thể tạo một mảng gồm 50 số ngẫu nhiên được lấy từ phân phối chuẩn:
a = rng.standard_normal(50)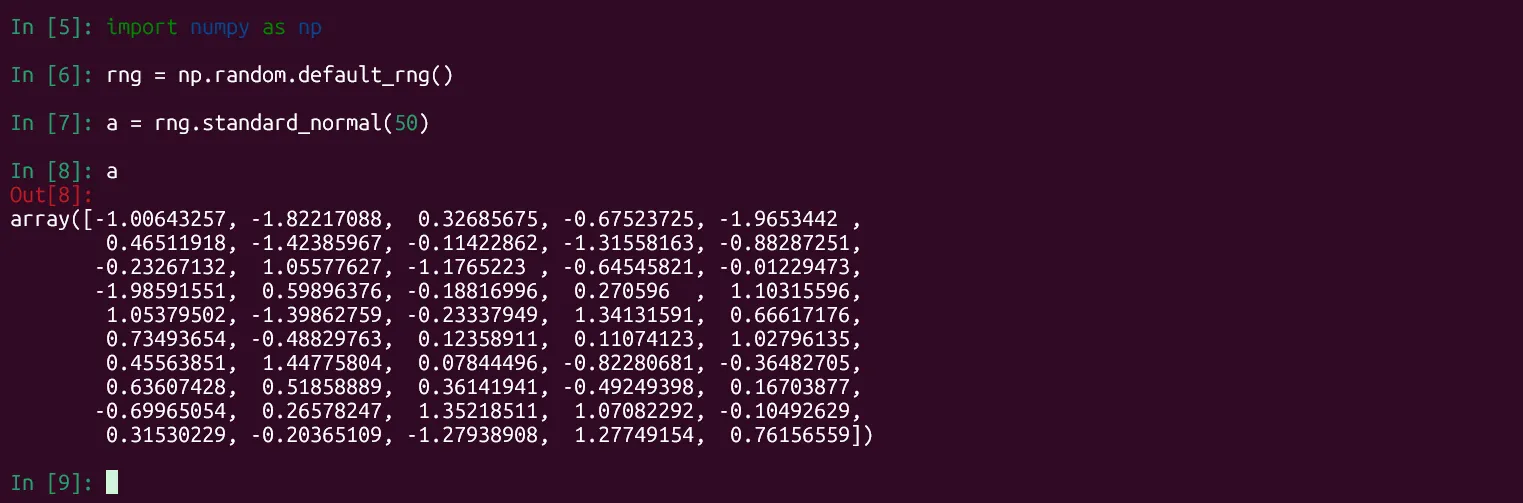 Màn hình IPython hiển thị lệnh tạo mảng 50 số ngẫu nhiên theo phân phối chuẩn bằng thư viện NumPy, ví dụ về tạo dữ liệu thử nghiệm trong Python.
Màn hình IPython hiển thị lệnh tạo mảng 50 số ngẫu nhiên theo phân phối chuẩn bằng thư viện NumPy, ví dụ về tạo dữ liệu thử nghiệm trong Python.
Thống Kê Mô Tả Cơ Bản Với Python và pandas
Việc tính toán các thống kê mô tả cơ bản trở nên cực kỳ dễ dàng khi sử dụng Python và thư viện pandas.
Chúng ta sẽ sử dụng bộ dữ liệu “tips” của Seaborn làm DataFrame mẫu:
import seaborn as snstips = sns.load_dataset('tips')Để xem các cột dữ liệu, hãy sử dụng phương thức head() đã đề cập ở trên:
tips.head()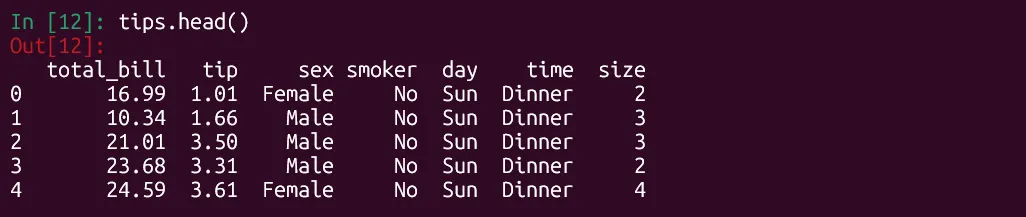 Kết quả lệnh tips.head() hiển thị 5 hàng đầu tiên của bộ dữ liệu 'tips' trong IPython, kiểm tra cấu trúc dữ liệu trước khi phân tích thống kê Pandas.
Kết quả lệnh tips.head() hiển thị 5 hàng đầu tiên của bộ dữ liệu 'tips' trong IPython, kiểm tra cấu trúc dữ liệu trước khi phân tích thống kê Pandas.
Tổng quan dữ liệu với describe()
Chúng ta có thể sử dụng phương thức describe() để lấy thống kê mô tả của tất cả các cột số trong DataFrame.
tips.describe()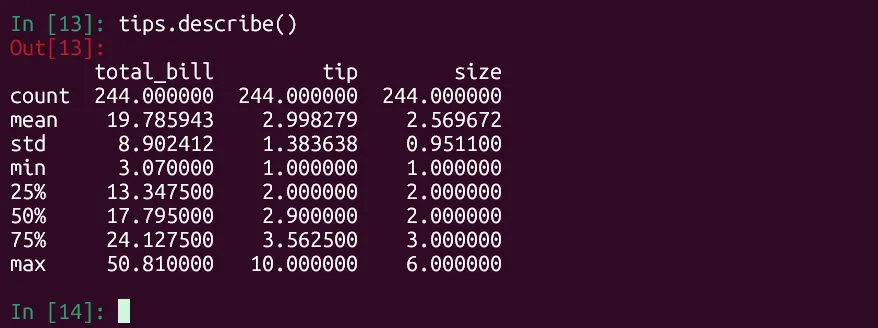 Kết quả lệnh tips.describe() trong IPython hiển thị thống kê mô tả cho các cột số trong DataFrame của Pandas, bao gồm trung bình, độ lệch chuẩn, phân vị.
Kết quả lệnh tips.describe() trong IPython hiển thị thống kê mô tả cho các cột số trong DataFrame của Pandas, bao gồm trung bình, độ lệch chuẩn, phân vị.
Pandas sẽ in dữ liệu cho các cột “total_bill”, “tip” và “size”. Kết quả này bao gồm số điểm dữ liệu, trung bình (mean), độ lệch chuẩn (standard deviation), giá trị tối thiểu (minimum value), tứ phân vị thứ nhất (lower quartile hay 25th percentile), trung vị (median hay 50th percentile), và tứ phân vị thứ ba (upper quartile hay 75th percentile).
Tính toán các chỉ số cụ thể: Trung bình, Trung vị, Độ lệch chuẩn, Phân vị
Bạn cũng có thể xem thống kê mô tả cho một cột riêng lẻ:
tips['total_bill'].describe()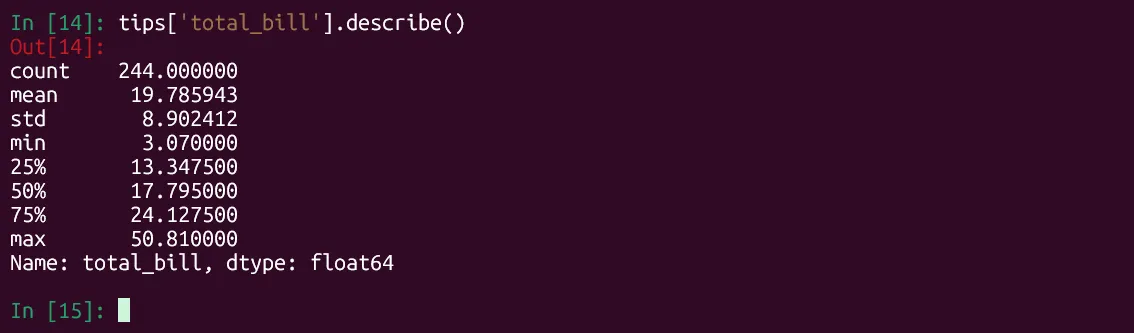 Kết quả thống kê mô tả cụ thể cho cột 'total_bill' của DataFrame trong Python, minh họa cách phân tích một biến số riêng lẻ với Pandas.
Kết quả thống kê mô tả cụ thể cho cột 'total_bill' của DataFrame trong Python, minh họa cách phân tích một biến số riêng lẻ với Pandas.
Hoặc để xem giá trị trung vị của tiền tip:
tips['tip'].median() Kết quả hiển thị giá trị trung vị của cột 'tip' trong DataFrame bằng Python, một ví dụ về tính toán chỉ số thống kê mô tả với Pandas.
Kết quả hiển thị giá trị trung vị của cột 'tip' trong DataFrame bằng Python, một ví dụ về tính toán chỉ số thống kê mô tả với Pandas.
Hồi Quy Tuyến Tính: Khám Phá Xu Hướng và Mối Quan Hệ
Thống kê mô tả cung cấp cái nhìn tổng quan về dữ liệu. Tuy nhiên, sức mạnh thực sự của phân tích dữ liệu đến từ việc tìm ra mối quan hệ giữa các biến. Hồi quy tuyến tính là một trong những cách đơn giản nhất để làm điều này.
Chúng ta có thể hình dung hồi quy tuyến tính là việc vẽ một đường thẳng phù hợp nhất với các điểm dữ liệu.
Hãy quay lại bộ dữ liệu “tips”. Chúng ta sẽ sử dụng Seaborn để vẽ biểu đồ mối quan hệ giữa tiền tip và tổng hóa đơn. Số tiền hóa đơn (biến độc lập) sẽ nằm trên trục x, và tiền tip (biến phụ thuộc) sẽ nằm trên trục y. Chúng ta có thể vẽ đường hồi quy trên biểu đồ phân tán để xem mức độ phù hợp của nó.
sns.regplot(x='total_bill',y='tip',data=tips)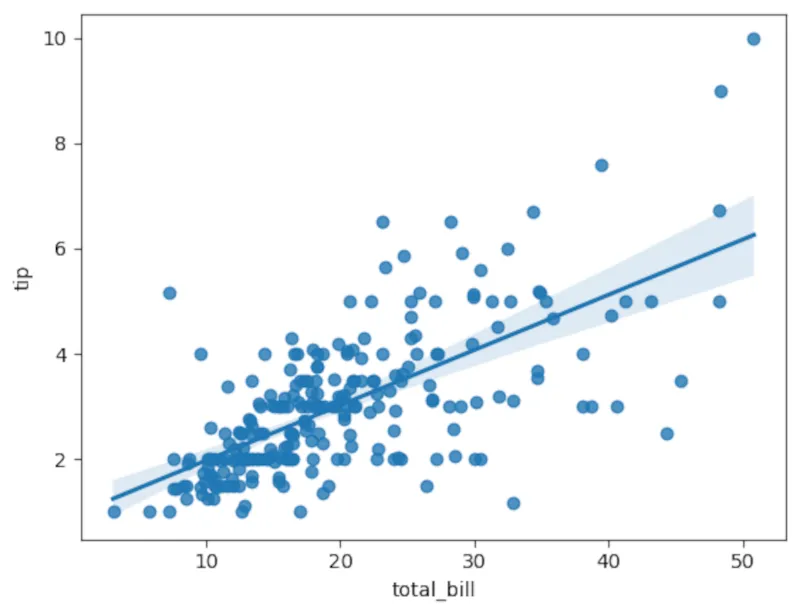 Biểu đồ hồi quy tuyến tính của tiền tip so với tổng hóa đơn được tạo bằng thư viện Seaborn trong Python, trực quan hóa mối quan hệ giữa các biến số.
Biểu đồ hồi quy tuyến tính của tiền tip so với tổng hóa đơn được tạo bằng thư viện Seaborn trong Python, trực quan hóa mối quan hệ giữa các biến số.
Phân tích hồi quy định lượng với Pingouin
Chúng ta cũng có thể thu được một phân tích chính thức hơn với thư viện Pingouin:
import pingouin as pgpg.linear_regression(tips['total_bill'],tips['tip'])Cột ngoài cùng bên trái sẽ chứa điểm chặn y (y-intercept) và hệ số cho giá trị x, trong trường hợp này là tổng hóa đơn. Điều này cho phép bạn tái tạo đường thẳng dưới dạng phương trình chuẩn dạng slope-intercept. Tuy nhiên, con số đáng chú ý là bình phương của hệ số tương quan, hay r². Trong ví dụ này, nó xấp xỉ 0.46, đây là một mức độ phù hợp khá tốt theo hướng tích cực, xác nhận những gì chúng ta đã thấy trong biểu đồ.
Kiểm Định Thống Kê: Đánh Giá Ý Nghĩa của Sự Khác Biệt
Một vấn đề thường xuyên phát sinh trong các thí nghiệm có nhóm đối chứng và nhóm thử nghiệm, chẳng hạn như thử nghiệm lâm sàng một loại thuốc mới, là xác định liệu sự khác biệt giữa hai nhóm có phải do ngẫu nhiên hay không. Các kiểm định thống kê giữa các nhóm có thể giúp chúng ta xác định liệu một sự khác biệt có ý nghĩa thống kê hay không.
Một trong những kiểm định phổ biến nhất trong nghiên cứu hiện đại là kiểm định t-test của Student, bởi vì nó rất tốt trong việc xử lý các mẫu nhỏ cần thiết trong các thí nghiệm.
Chúng ta sẽ sử dụng bộ tạo số ngẫu nhiên của NumPy để tạo một vài nhóm mô phỏng, mỗi nhóm gồm mười phần tử:
import numpy as nprng = np.random.default_rng()a = rng.standard_normal(10) * 20b = rng.standard_normal(10) * 50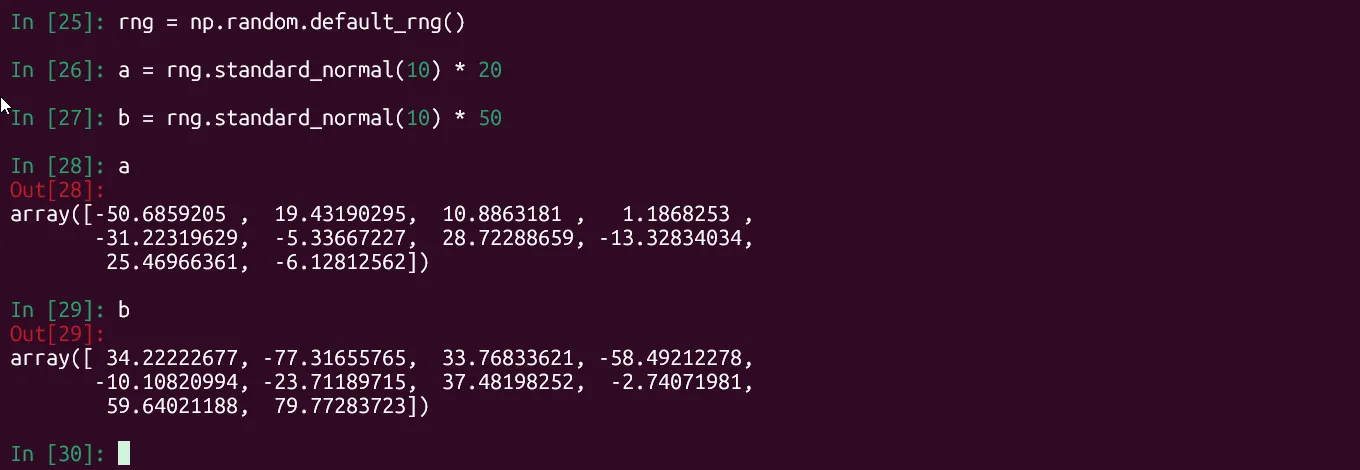 Màn hình IPython hiển thị lệnh tạo hai nhóm dữ liệu ngẫu nhiên 'a' và 'b' bằng thư viện NumPy, chuẩn bị dữ liệu cho kiểm định t-test trong Python.
Màn hình IPython hiển thị lệnh tạo hai nhóm dữ liệu ngẫu nhiên 'a' và 'b' bằng thư viện NumPy, chuẩn bị dữ liệu cho kiểm định t-test trong Python.
Pingouin có một hàm t-test được tích hợp sẵn để kiểm định giả thuyết không (null hypothesis) rằng không có sự khác biệt đáng kể giữa hai nhóm:
pg.ttest(a,b) Kết quả kiểm định t-test từ thư viện Pingouin trong Python, hiển thị p-value để đánh giá sự khác biệt thống kê giữa hai nhóm dữ liệu.
Kết quả kiểm định t-test từ thư viện Pingouin trong Python, hiển thị p-value để đánh giá sự khác biệt thống kê giữa hai nhóm dữ liệu.
Con số để xác định ý nghĩa trong kết quả là giá trị p (p-value). Chúng ta sẽ sử dụng p-value là 0.05 để xác định ý nghĩa. Kết quả xấp xỉ 0.61. Vì con số này cao hơn 0.05, chúng ta không thể bác bỏ giả thuyết không, do đó chúng ta kết luận rằng các kết quả này không có ý nghĩa thống kê.
Những ví dụ này chỉ là bề nổi của tảng băng chìm khi nói đến phân tích dữ liệu trong Python. Giờ đây, khi bạn đã thấy các thao tác dữ liệu bằng Python có thể dễ dàng và mạnh mẽ đến mức nào với sự trợ giúp của các thư viện này, bạn có thể hiểu tại sao Python là một ngôn ngữ được lựa chọn hàng đầu cho phân tích dữ liệu và khoa học dữ liệu. Bạn nghĩ sao về tiềm năng của Python trong lĩnh vực này? Hãy để lại bình luận bên dưới nhé!